源码解读之 HashMap
java.util.Map 的实现类 HashMap、Hashtable、LinkedHashMap、TreeMap、ConcurrentHashMap 之间的关系
HashMap 与 HashTable 的区别?
- HashMap 线程不安全,Hashtable 线程安全
- HashMap 允许 K/V 都为 null;后者 K/V 都不允许为 null
- HashMap 继承自 AbstractMap 类;而 Hashtable 继承自 Dictionary 类
ConcurrentHashMap 和 HashTable 的区别?
ConcurrentHashMap 结合了 HashMap 和 HashTable 二者的优势。HashMap 没有考虑同步,HashTable 考虑了同步的问题。
但是 HashTable 在每次同步执行时都要锁住整个结构,ConcurrentHashMap 锁的方式是稍微细粒度的
同步集合 HashTable 与并发集合 ConcurrentHashMap ?
Collections.synchronizedMap() 方法可以获取一个线程安全的 map,称为同步集合,锁住整个方法(粗粒度)
ConcurrentHashMap 是并发集合,锁是细粒度的,性能更高
ConcurrentHashMap,它内部细分了若干个小的 HashMap,称之为段(Segment)。默认情况下一个 ConcurrentHashMap 被进一步细分为 16 个段,既就是锁的并发度(分段锁)
不管是同步集合还是并发集合,都能保证线程安全,但建议使用并发集合
LinkedHashMap 和 Treemap
LinkedHashMap 按插入顺序存储,TreeMap 可对键排序
存储结构
java 7 采用数组 + 单向链表,java 8 采用数组 + 单向链表 + 红黑树
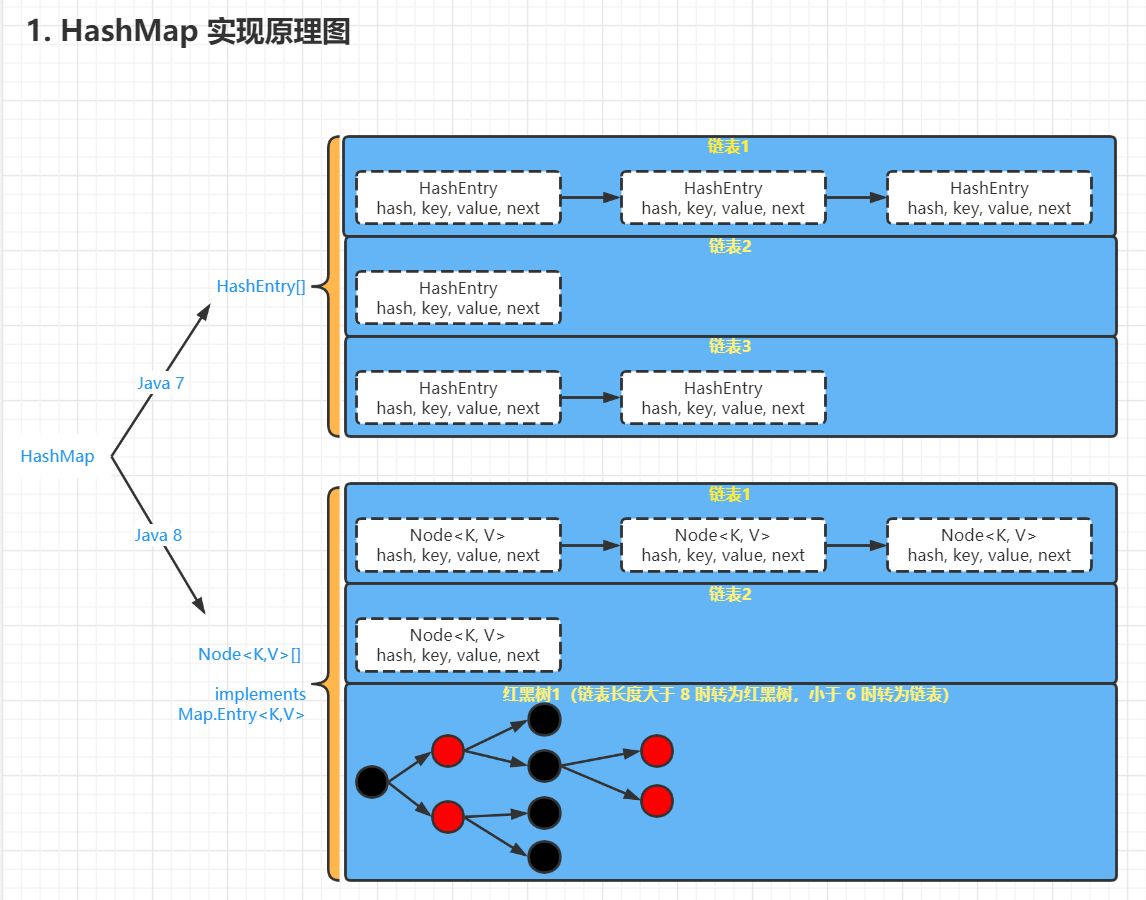
HashMap 就是使用哈希表来存储的。哈希表为解决冲突,可以采用开放地址法和链地址法等来解决问题,Java 中 HashMap 采用了链地址法。链地址法,简单来说,就是数组加链表的结合。在每个数组元素上都有一个链表结构,当数据被 Hash 后,得到数组下标,把数据放在对应下标元素的链表上 。
Hash 算法计算结果越分散均匀,Hash 碰撞的概率就越小,map 的存取效率就会越高
如果哈希桶数组很大,即使较差的 Hash 算法也会比较分散,如果哈希桶数组数组很小,即使好的 Hash 算法也会出现较多碰撞,所以就需要在空间成本和时间成本之间权衡,其实就是在根据实际情况确定哈希桶数组的大小,并在此基础上设计好的 hash 算法减少 Hash 碰撞
几个字段:
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; //默认初始化大小 16
int threshold; // 所能容纳的key-value对极限,threshold = length * loadFactor,length默认16,当超过threshold就要扩容,length就是Entry数组的长度,一定是2的n次方,即每次扩容一倍
final float loadFactor; // 负载因子,默认0.75
int modCount; //记录HashMap内部结构发生变化的次数
int size; //实际存储的kv对个数即使负载因子和 Hash 算法设计的再合理,也免不了会出现拉链过长的情况,一旦出现链表过长,则会严重影响 HashMap 的性能。于是,在 JDK1.8 版本中,对数据结构做了进一步的优化,引入了红黑树。而当链表长度太长(默认超过 8)时,链表就转换为红黑树,利用红黑树快速增删改查的特点提高 HashMap 的性能
根据 key 获取哈希桶数组索引位置
不管增加、删除、查找键值对,定位到哈希桶数组的位置都是很关键的第一步
这里的 Hash 算法本质上就是三步:取 key 的 hashCode 值、高位运算、取模运算
//源码的实现(方法一+方法二):
//方法一:jdk1.8 & jdk1.7
static final int hash(Object key) {
//key.hashCode() 第一步.取hashCode值
//h >>> 16 第二步.高位参与运算
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
//方法二:jdk1.7的源码,jdk1.8没有这个方法,但是实现原理一样的
static int indexFor(int h, int length) {
//第三步.取模运算,相当于h%length,但效率更高
return h & (length-1);
}put 方法原理
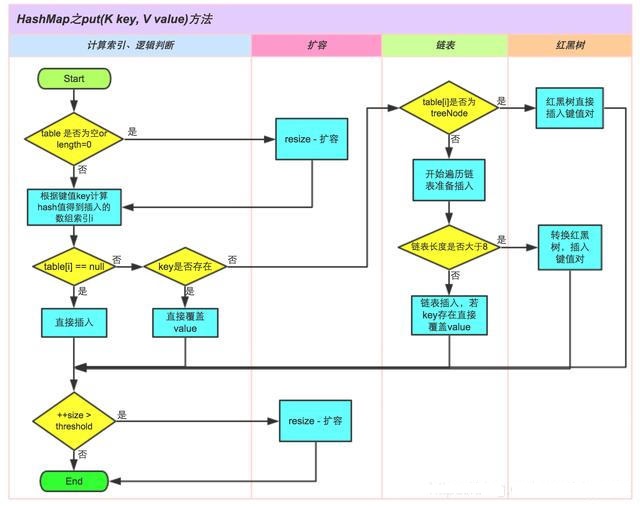
注:table 就是数组,table[i]就是数组的第 i 个元素
- 判断键值对数组 table 是否为空或为 null,否则执行 resize()进行扩容;
- 根据键值 key 计算 hash 值得到插入的数组索引 i,如果 table[i]==null,直接新建节点添加,转向 6,如果 table[i]不为空,转向 3
- 判断 table[i]的首个元素是否和 key 一样,如果相同直接覆盖 value,否则转向 4,这里的相同指的是 hashCode 以及 equals
- 判断 table[i] 是否为 treeNode,即 table[i] 是否是红黑树,如果是红黑树,则直接在树中插入键值对,否则转向 5
- 遍历 table[i],判断链表长度是否大于 8,大于 8 的话把链表转换为红黑树,在红黑树中执行插入操作,否则进行链表的插入操作;遍历过程中若发现 key 已经存在直接覆盖 value 即可
- 插入成功后,判断实际存在的键值对数量 size 是否超多了最大容量 threshold,如果超过,进行扩容
扩容机制
数组是无法自动扩容的,方法是使用一个新的数组代替已有的容量小的数组
扩容是一个特别耗性能的操作,所以当程序员在使用 HashMap 的时候,估算 map 的大小,初始化的时候给一个大致的数值,避免 map 进行频繁的扩容
为什么链表长度超过 8 就转化为红黑树?
HashMap 在 jdkL8 之后弓|入了红黑树的概念,表示若桶中链表元素超过 8 时,会自动转化成红黑树;若桶中元素小于等于 6 时,树结构还原成链表形式。
原因:
红黑树的平均查找长度是 log(n), 长度为 8, 查找长度为 log(8)=3, 链表的平均查找长度为 n/2, 当长度为 8 时,平均查找长度为 8/2=4, 这才有转换成树的 必要;链表长度如果是小于等于 6, 6/2=3, 虽然速度也很快的,但是转化为树结构和生成树的时间并不会太短。
还有选择 6 和 8 的原因是:
中间有个差值 7 可以防止链表和树之间婕的转换。假设一下,如果设计成链表个数超过 8 则链表转换成树结构,链表个数小于 8 则树结构转换成链表,如果一个 HashMap 不停的插入、删除元素,链表个数在 8 左右勾胭,就会顷繁的发生树转链表、链表转树,效率会很低。
hashmap 的 key 为自定义对象时,要重写 equals 和 hashcode 方法
因为 hashmap 是根据哈希值计算的,当自定义对象的属性完全相同,但 hashcode 可能不同,因此要重写 hashcode 方法。重写 hashcode 则 equals 必须重写